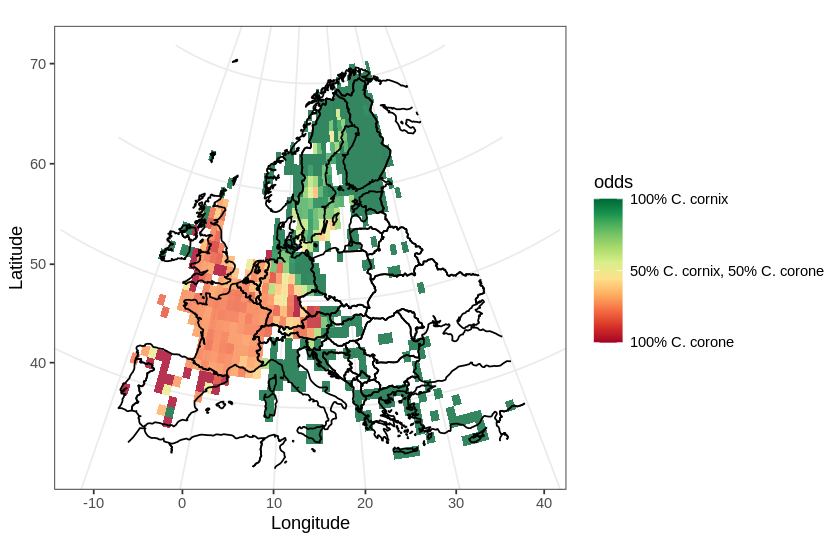
Diversity indices are a common descriptive statistic used in biodiversity informatics. Diversity indices typically express the species richness of a given habitat or area. The α-diversity index is suitable when studying a single habitat and is expressed by a single number. There are several commonly used equations used to compute α-diversity. In this example, I will be using the Simpson’s diversity index, which is computed by the formula:
![\[D = 1 - \sum_{i=1}^{S}p_i^2\]](http://biodiv.smultron.org/wp-content/ql-cache/quicklatex.com-55f32c820d77a3a7dc38c88992946e12_l3.png "Rendered by QuickLaTeX.com")
Where S is the number of species in the sample and p is the proportion of a particular species. The Simpson’s diversity index is thus more influenced by common species rather than by rare species and is often considered to be an index reflecting the actual species diversity in a sample.
To illustrate this, I will use will use data obtained from GBIF. Remember, α-diversity is suitable for expressing the diversity within a single habitat, so I will obtain data accordingly. Here I chose the Tiergarten, a large (210 hectare) park in central Berlin.
Continue reading “Computing α-diversity”