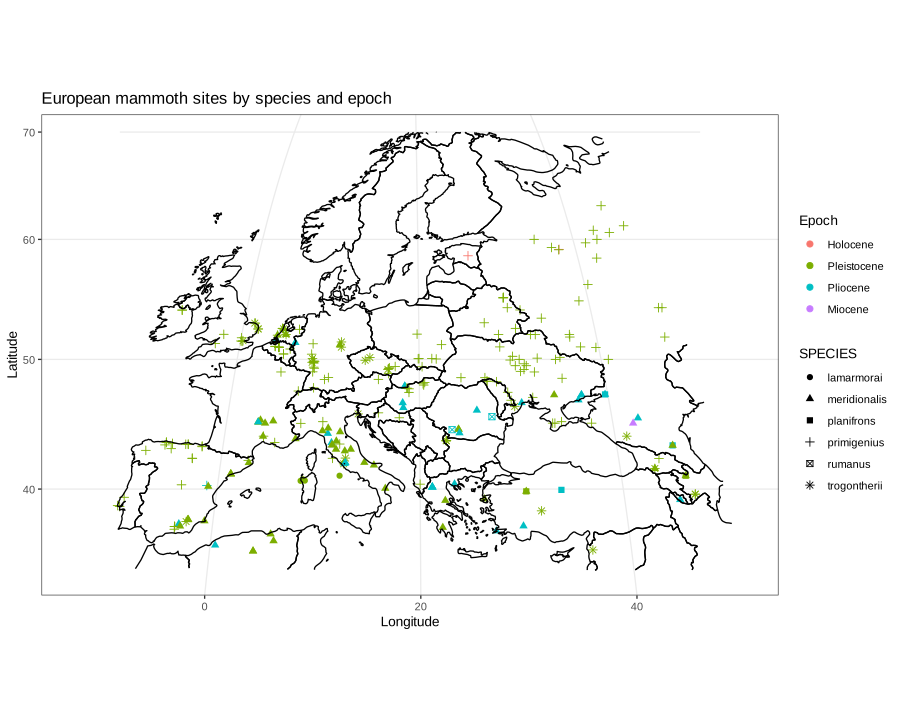
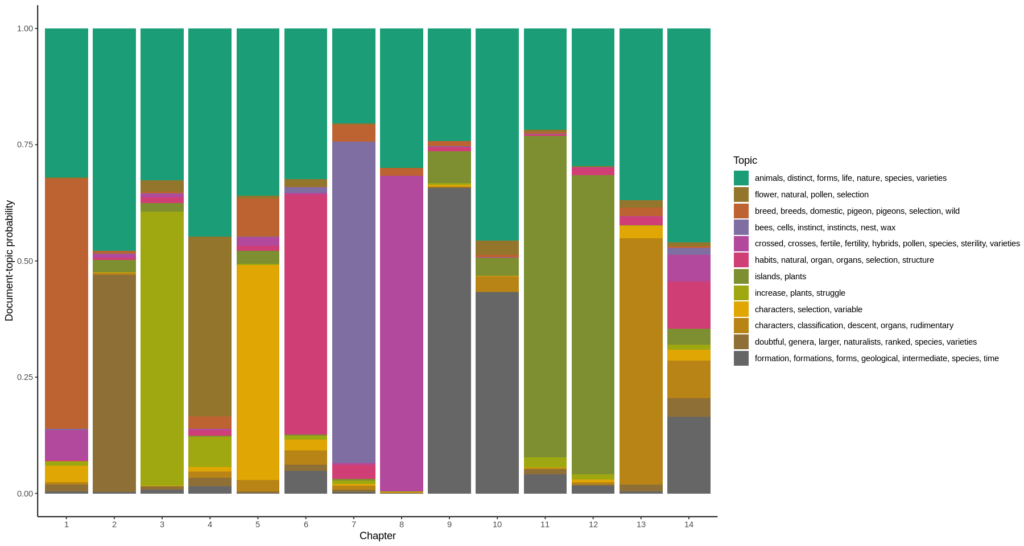
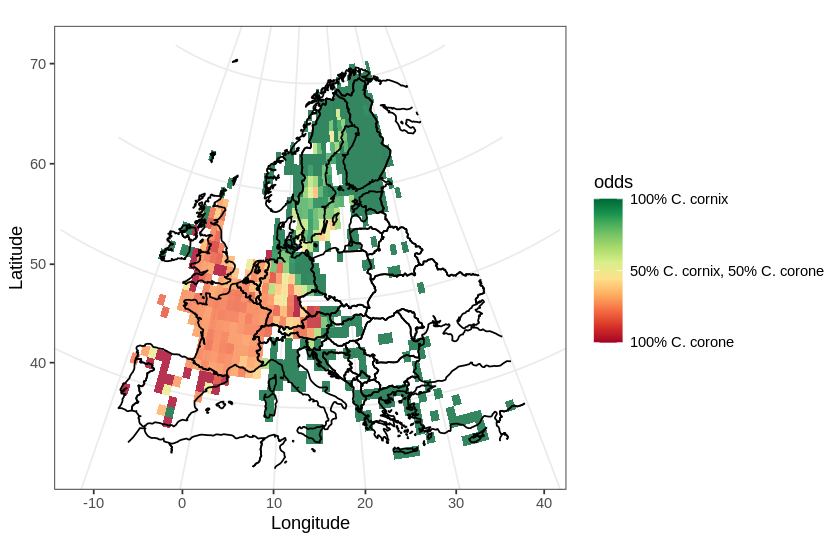
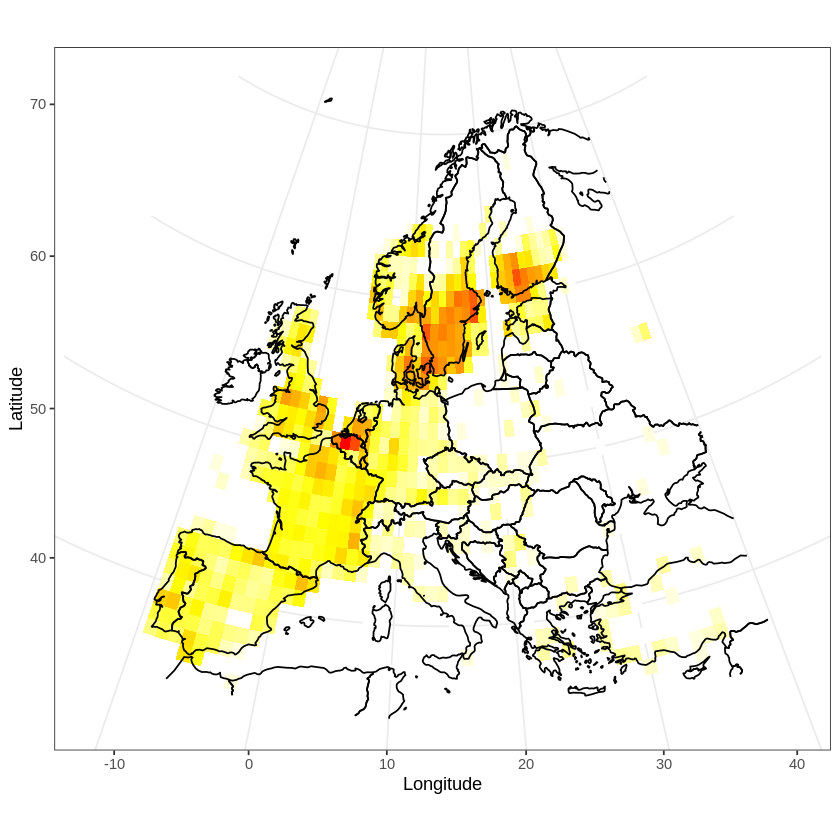
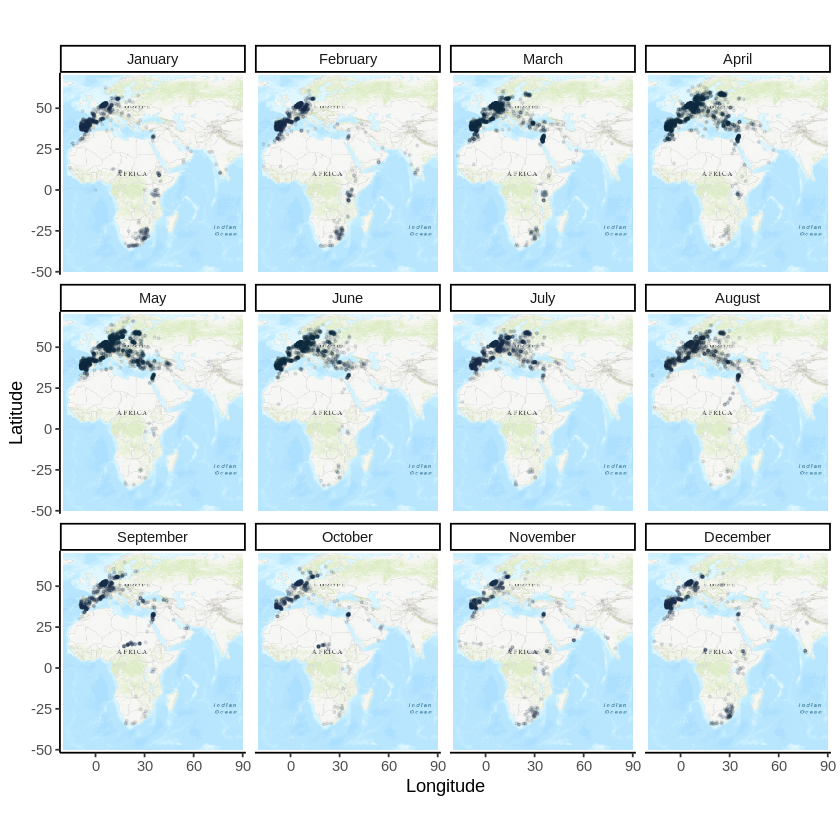
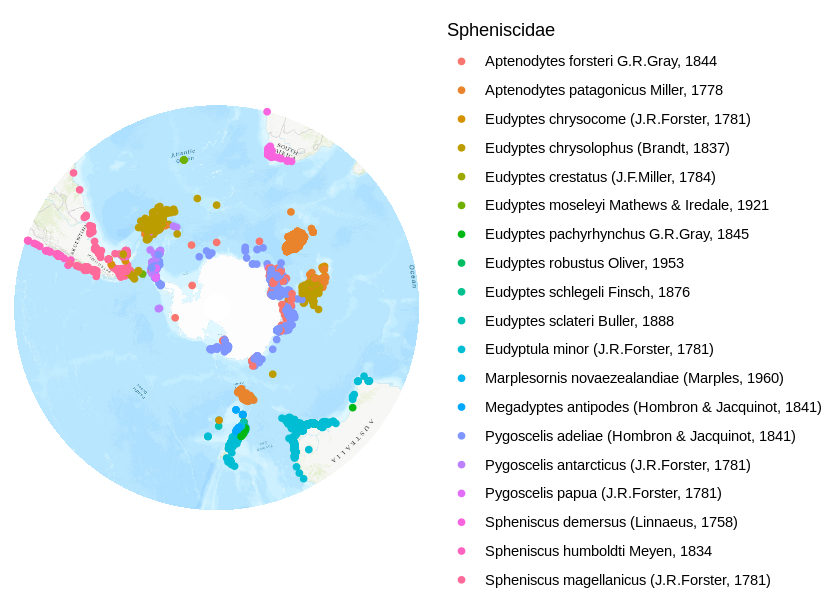
Taxonomic trees are ubiquitous in biodiversity software. A very common application is using a tree to allow the users to browse the data. Other applications are: training classification models, curating a collection, visualizing research results etc.
Data is often stored in a relational database, such as MySQL. Unfortunately, relational databases are not particularly well suited for storing tree structures. Yet the choice of a database may be guided by more important requirements, and so the taxonomic tree is sometimes implemented as an afterthought. The result can be a structure that is difficult to maintain and to query, sometimes requiring more work than expected to maintain and finally yielding a less satisfying experience for the end user.
I will show some counterexamples, and how get a better result by using a data structure called “nested set”.
Continue reading “Storing a taxonomic tree in a relational database”